LM Studio
LM Studio — это кроссплатформенное приложение с графическим интерфейсом, предназначенное для запуска языковых моделей (LLM) локально на вашем компьютере. Программа поддерживает модели в формате GGUF, оптимизированном для эффективной работы на потребительском оборудовании.
Преимущества:
- Приватность — все данные обрабатываются локально.
- Бесплатность — отсутствуют скрытые платежи или подписки.
- Интуитивный интерфейс — не требует навыков программирования.
- Поддержка множества моделей — доступ к популярным LLM через встроенный каталог.
- Гибкая настройка — контроль над параметрами генерации.
Маркировка моделей:
- Q — Квантование. Указывает, что модель была квантована — процесс уменьшения точности числовых значений весов для сокращения размера модели и ускорения вывода. Цифра после Q обозначает битность (количество бит на вес):
- Q2 — 2 бита на вес (максимальное сжатие, низкая точность).
- Q3 — 3 бита на вес.
- Q4 — 4 бита на вес (оптимальный баланс для большинства задач).
- Q5 — 5 бит на вес.
- Q6 — 6 бит на вес.
- Q8 — 8 бит на вес (высокая точность, минимальное сжатие).
- K — Веса сгруппированы (обычно по 32, 64 или 128 значений). Каждая группа имеет свои параметры масштабирования (scale) и нулевой точки (zero-point).
- 0 — Устаревшая схема без группировки, менее эффективная.
- b — Размер веса. Чем больше, тем лучше.
- S (Small) — Низкая точность, высокая скорость, минимальный размер.
- M (Medium) — Оптимальный баланс между качеством и производительностью.
- L (Large) — Максимальная точность, но высокие требования к ресурсам.
Примеры расшифровки моделей:
- Q3_K_L — Квантованная модель с 3-битными весами, группировка весов, максимальная точность.
- Q4_K_M — Квантованная модель с 4-битными весами, группировка весов, средняя точность (оптимальный баланс).
- Q6_K — Квантованная модель с 6-битными весами, группировка весов, стандартная точность.
- 8_0 — Квантованная модель с 8-битными весами, без группировки (устаревшая схема), стандартная точность.
- F16 — Полноразмерная модель с 16-битными весами (половинная точность), без квантования.
Популярные LLM-модели
Китайские модели (семейства GLM, Qwen, DeepSeek)
GLM-4.6V-Flash (9B):
- Особенности: Мультимодальная модель («V» — Vision), оптимизированная для сверхбыстрой обработки текста и изображений.
- Назначение: Идеальна для работы на пользовательских устройствах (смартфоны, ПК) и в Edge-системах. Используется для мгновенных визуальных ответов в ИИ-ассистентах.
Qwen3:
- Особенности: Флагманское поколение моделей от Alibaba Cloud. В 2025 году Qwen3 закрепила лидерство в многоязычных задачах и программировании.
- Преимущества: Показывает одни из лучших результатов в тестах на логику и математику среди open-source моделей, часто превосходя западные аналоги в задачах кодинга.
deepseek-r1-0528-qwen3-8b:
- Особенности: Гибридная модель — дообученная версия Qwen3 от DeepSeek.
- Назначение: Индекс «r1» указывает на использование методов Reasoning (рассуждения). Модель оптимизирована для глубокого анализа перед ответом, что делает её эффективной для сложных логических цепочек, несмотря на компактный размер (8B).
Французские модели (Mistral AI)
Mistral-3 (3B, 8B, 14B):
- Особенности: Новое поколение «малых» моделей для сегмента on-device AI.
Различия:
- 3B — для смартфонов.
- 8B — сбалансированный стандарт для чат-ботов.
- 14B — мощная модель, конкурирующая с тяжелыми системами по пониманию контекста.
Devstral Small:
- Особенности: Специализированная модель для разработчиков (Software Engineering).
- Назначение: Оптимизирована для генерации кода, отладки и написания документации. «Small» указывает на высокую скорость работы при сохранении точности синтаксиса популярных языков программирования.
Американские модели (Google и OpenAI)
Gemma 3:
- Особенности: Открытая модель (open-weight) от Google, построенная на технологиях Gemini.
- Преимущества: Улучшена работа с длинным контекстом и мультимодальностью. Стандарт для исследователей благодаря интеграции с Vertex AI и библиотеками Google.
OpenAI-GPT OSS 20B:
- Особенности: Уникальная модель с открытыми весами (OSS) на 20 млрд параметров.
- Назначение: Сочетает фирменный «стиль» общения GPT, высокую этическую фильтрацию и отличные способности к суммаризации текстов. Доступна для локального запуска на мощных рабочих станциях.
Начало работы
После запуска LM Studio перейдите во вкладку Model Search (Поиск моделей). Найдите, выберите и загрузите нужную LLM-модель. Выбирайте модель, соответствующую вашим аппаратным возможностям.
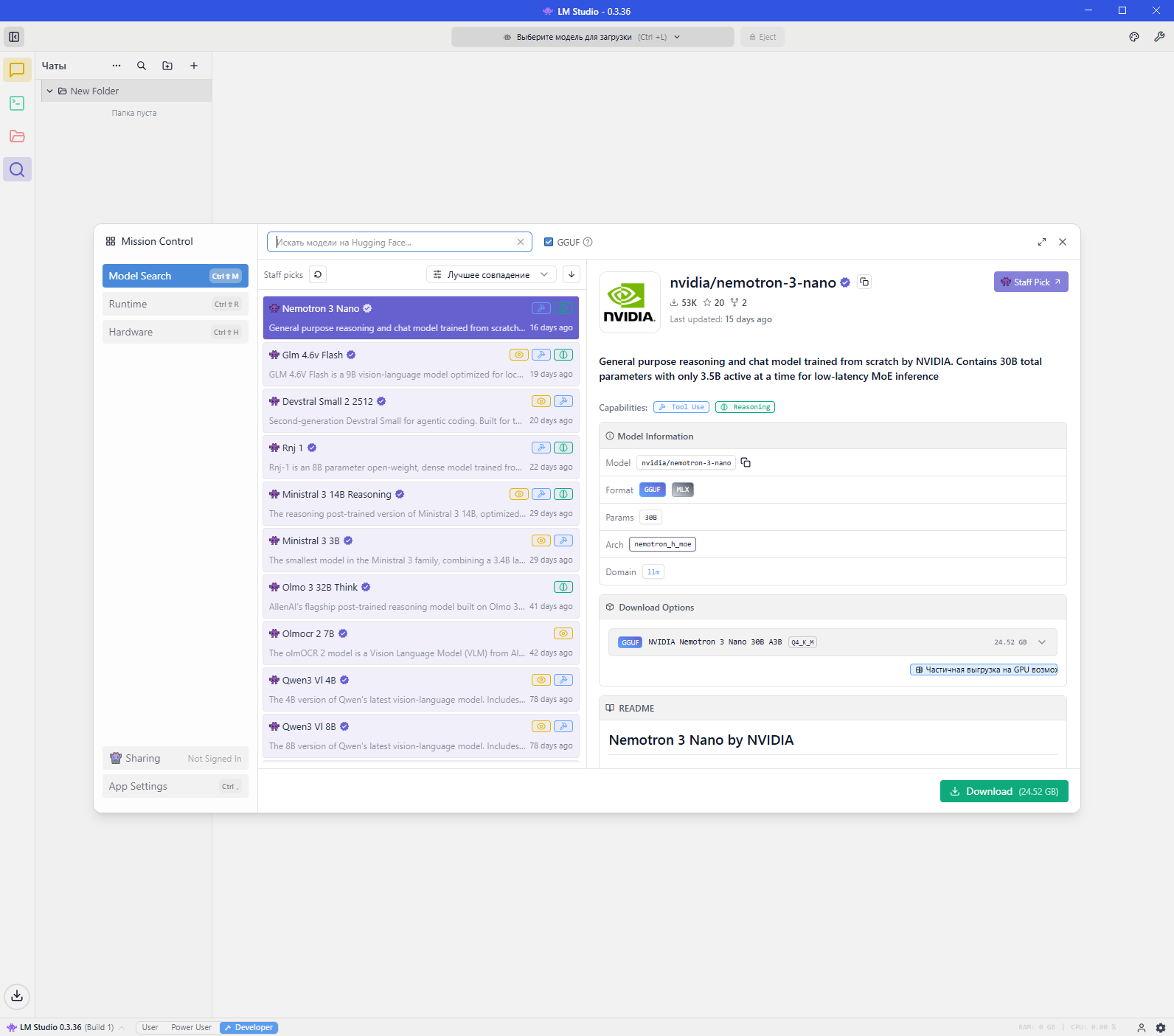
Требования к оборудованию:
- Для запуска большинства современных локальных моделей среднего размера (7B–13B параметров) рекомендуется 32 ГБ ОЗУ и более.
- Дискретная видеокарта с большим объемом VRAM значительно ускоряет обработку.
- При недостатке VRAM программа автоматически использует RAM и CPU. Модель будет работать даже на встроенной графике, но скорость генерации текста снизится.
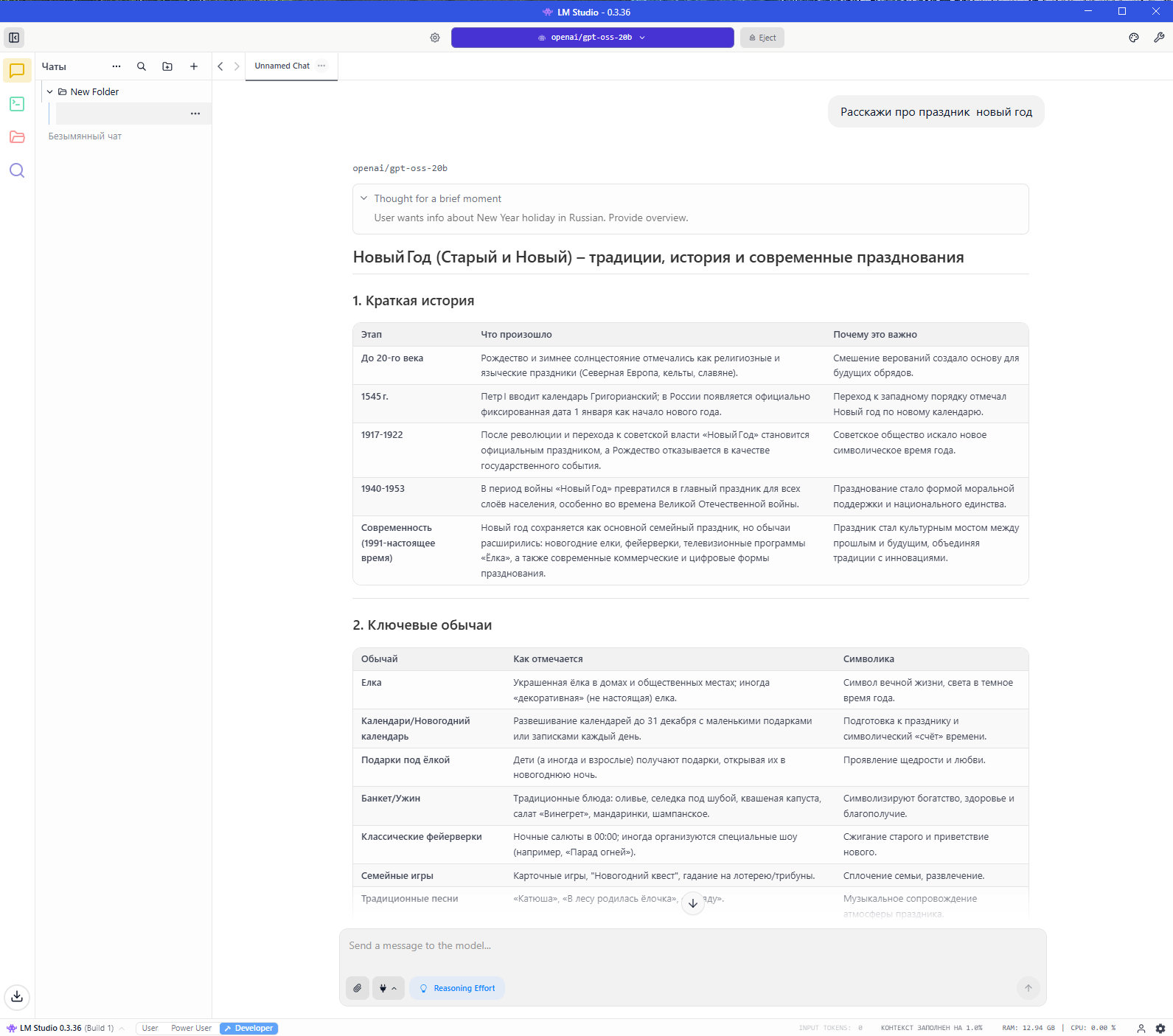
Для теста была загружена LLM модель OpenAI-GPT OSS 20B и выбран размер контекста 7200 токенов.
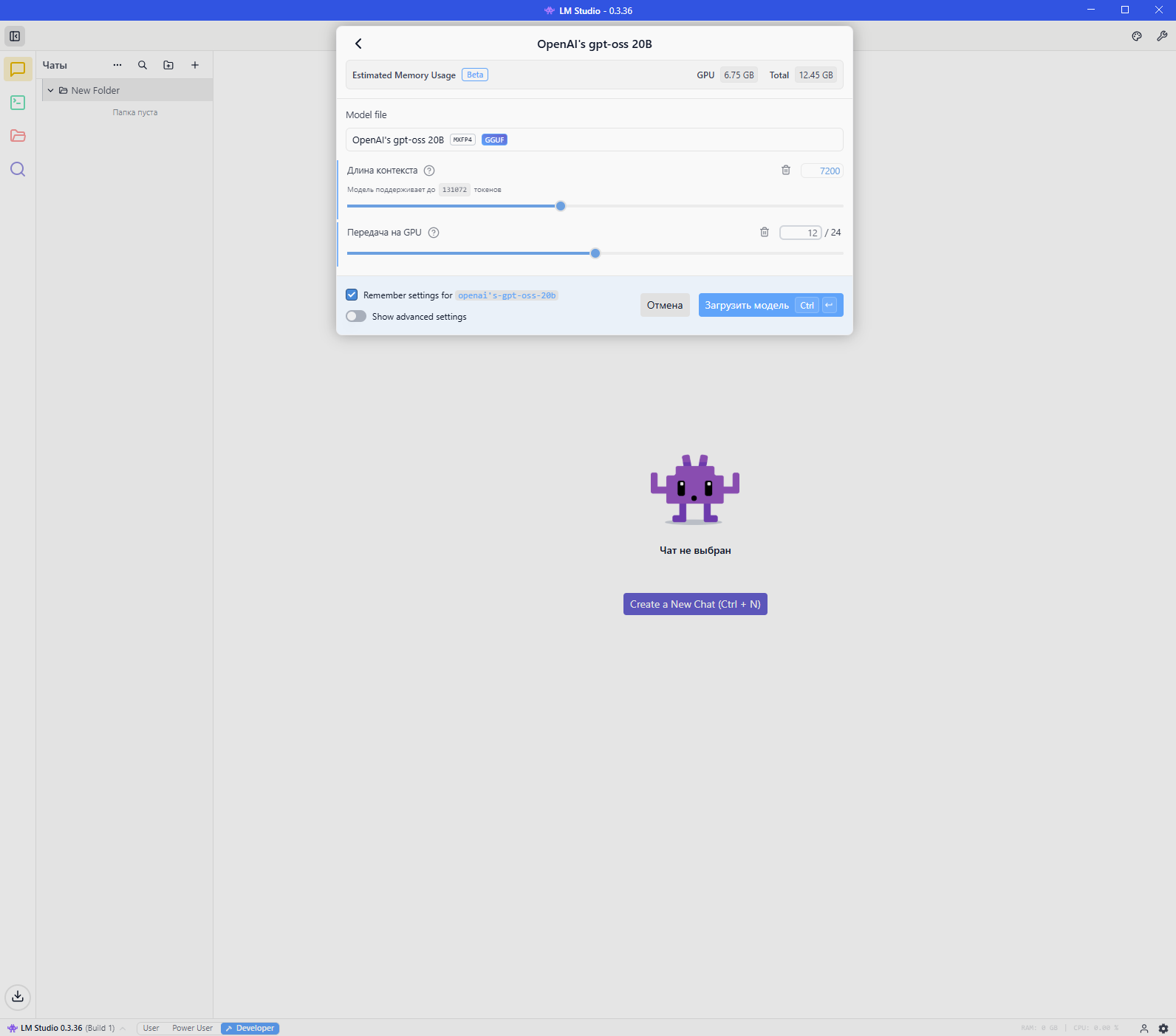
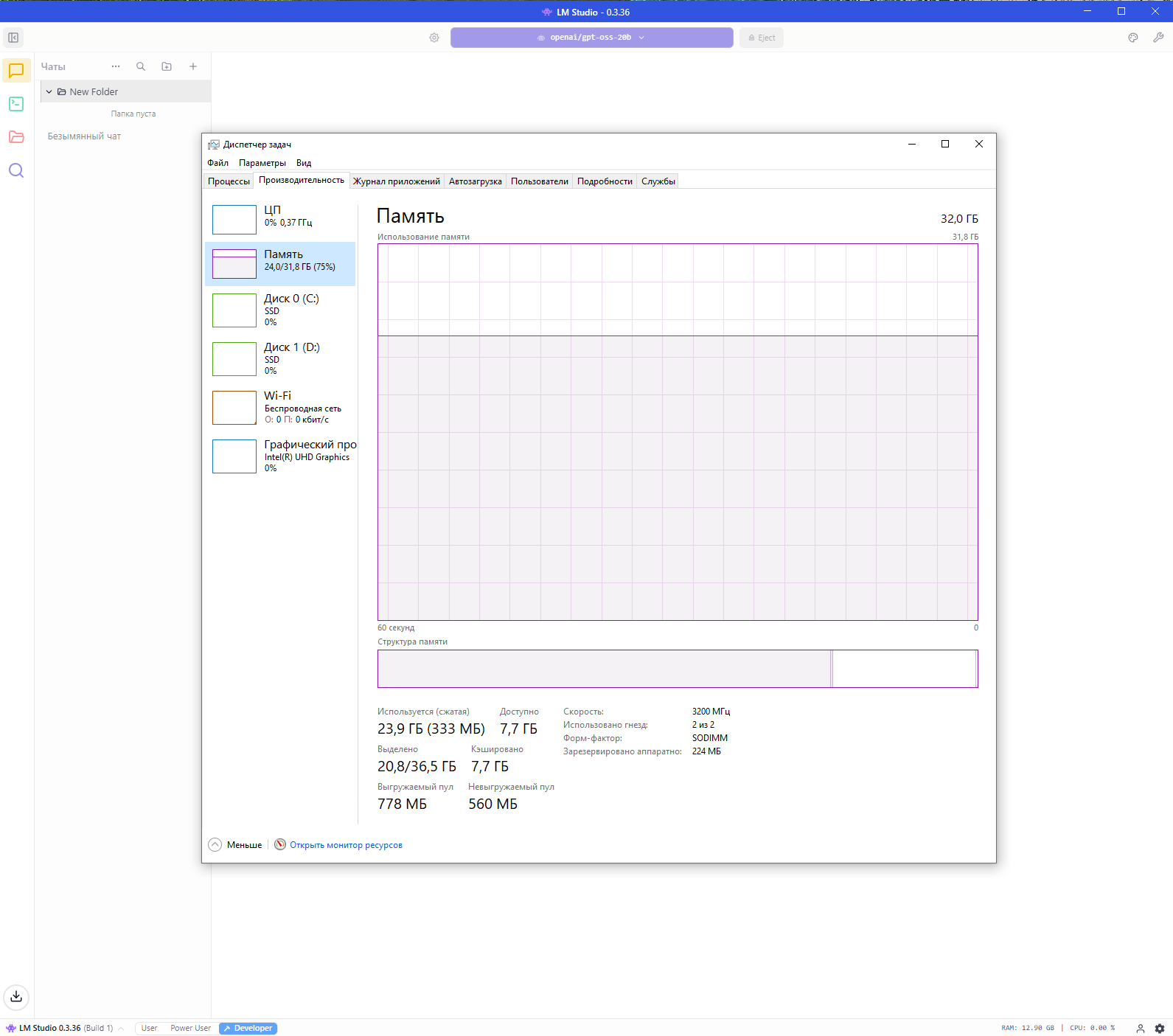

Производительность:
- Мобильный процессор Intel Core i3-1315U 1.20 GHz
- Оперативная память 32.0 ГБ
- Видеоадаптер Intel UHD Graphics
- Размер контекста 7200 токенов
- Нейросеть OpenAI-GPT OSS 20B скорость ответа 5.19 токенов/сек, размер ответа на вопрос "Расскажи про праздник новый год" составил 1958 токенов.